Data, metadata, and synthetic data: how it can help you master data governance
A simple seven-step plan helps SMBs govern data, metadata, and synthetic data for better AI results.

Key takeaways for how to master data governance:
- Metadata is the backbone of a workable data governance program—it makes data findable, trustworthy, and AI-ready.
- Synthetic data can speed analytics and protect privacy, but it must sit inside governance (validation + policies) to avoid bias and leakage.
- For effective governance of data, metadata, and synthetic data, organizations should institute a roadmap that includes a data governance council, clear rules around data classification/usage, and protocols for the proper archiving of data.
Master data governance by minding your data details
Do you feel like your company’s overall data and IT systems aren’t ready for the oncoming AI revolution? Chances are, you still need to master data governance around your AI—and you’re not alone.
According to Gartner, 63% of organizations lack AI-ready practices for data, and another 60% say they’ve abandoned AI projects because of poor results and inaccurate data. There are many reasons for this. But the most common problem is one many organizations often overlook: how it manages and classifies organizational data, metadata, and synthetic data.
In the rush to install new AI tools and launch new processes, the finer details of data classification, permissions, and types can be easy to miss. But, if you get data management right from the beginning, it can be the biggest friend your AI initiative could ever have—and the key to getting the most out of your information.
While a comprehensive data governance program has several aspects, minding data access and classification is a good start. First, let’s break down the differences between data, metadata, and synthetic data, and how they can affect data governance overall.
Data, metadata, and synthetic data: How they differ
What is data?
Data is a broad term used to describe all your operational and analytic records. This includes structured data, such as databases and spreadsheets, as well as unstructured data such as email messages, documents, and images. Along with your employees, data is your most precious organizational resource, and the raw material for digital transformation, analytics, and AI. Effective governance ensures that your data is accurate, secure, and used ethically, supporting compliance and business outcomes.
What is metadata?
The question “What is metadata?” can be confusing. Metadata isn’t the data itself. It is “data about data”—the identifiers used to describe various facets of the information and improve its usability throughout its lifecycle. This includes business definitions, data ownership, quality roles, and sensitivity labels. Metadata management tools help teams understand what data they have, where it came from, and how it should be used.
For AI and analytics, metadata is critical, as it makes data discoverable, reusable, and trustworthy. Metadata is what makes automated policy enforcement possible. Combined with tools like access controls and retention windows, metadata helps your system understand how your data has been used in the past and how it should be used in the future.
What is synthetic data?
Synthetic data is the information you create to stand in for other data sets. For instance, have you ever seen an order confirmation come in with your credit card number represented by a series of XX’s followed by the last four digits of your number? This is synthetic data generation, and it is used whenever information needs to be shared that is too sensitive to be shared fully inside or outside the organization. The synthetic data set stands in for that data, allowing it to be attached to other files so the information is properly grouped. Synthetic data generation is valuable for safer sharing, software testing, and AI training when real data is risky, scarce, or prone to cause biased search results.
Why good data classification matters to your business
When you use your data well, it can help you to unlock value from your AI and analytics. Here’s some of the benefits your business can expect from the proper use of data classification in your data governance framework.
Findability and trust. Metadata acts as a map and a passport for your data. When you build your catalogs and glossaries on metadata, it will show what data exists, who owns it, and whether it’s fit for AI or analytics. This saves your team time, ensuring they only get the best results.
Policy adherence. Metadata and synthetic data can be the carriers for your governance policies. Sensitivity labels, retention windows, and access rules can be embedded as metadata, allowing tools to automatically enforce data governance policies. For instance, metadata can trigger automatic archiving or deletion of data, restrict access based on roles, and ensure compliance with privacy regulations. You’ll not only reduce manual errors, but you’ll also keep governance scalable as your data volumes grow.
Faster runs times with less waste. When metadata and synthetic data generation are well managed, AI models can quickly identify relevant, high-quality data, reducing time spent wrangling and minimizing Information it doesn’t need. This accelerates analytics and AI projects, so your organization can realize value faster with fewer resources.

Better data security. Many organizations are seeing significant data leaks because of their AI tools, allowing unauthorized employees or even outsiders to access data they should not have. Proper metadata and synthetic controls, paired with a full Responsible IT Architecture suite, will help keep these bad results at bay.
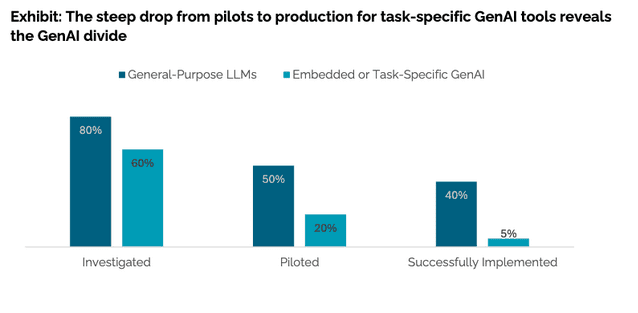
Caption: According to the latest analysis from McKinsey, general purpose large-language models (LLMs) are being used more, and more successfully, than embedded or task-driven AI programs/widgets. This points to the possibility that AI programs trained on specific, internal data are struggling to perform in many organizations. Source: McKinsey, “The State of AI: How Organizations Are Rewiring to Generate Value”
A seven-step SMB data governance roadmap for your data, metadata, and synthetic data
Now that we’ve defined the importance of managing your data classifications, how do you put best practices in place surrounding it? It will take a group effort at your company, requiring buy-in from across the organization to make it a pillar of your data governance framework. Here’s what we recommend:
Step 1: Name an executive sponsor and small data council
Any data governance program should start by appointing an executive sponsor, preferably one with the authority to champion data initiatives throughout the organization and secure resources. Then, form a small data council with representatives from IT, finance, and operations. This group will convene to help write AI and data governance policies, set priorities, and act as a bridge between leadership and technical teams. Working with your internal IT department as well as any managed service providers you may have, they can approve written policies, direct risk assessments, and provide ongoing oversight.
Step 2: Conduct a thorough data inventory
Before your program can start, your council should oversee a thorough inventory of all your data assets, including databases, files, SaaS platforms, and cloud services. Assign ownership for each data set and classify data by sensitivity, such as public, internal, confidential, or regulated categories. Use a simple template to record systems, owners, and classification.
Ideally, every department in your company should take time to think about the information that they generate and how they store it. Older files should be archived in such a way that AI won’t be parsing it. Newer information should be prioritized in stored in a consistent way that’s easy for both bots and employees to find.
Learn more about data governance frameworks: Integris blog “What is data governance?”
Step 3: Stand up a lightweight catalog and glossary
To operate optimally in the AI era, it’s important to classify your data according to data catalog vocabulary (DCAT) standards. This classification vocabulary is designed to make data catalogs interoperable, discoverable, and easier to aggregate across organizations and platforms. The catalog should include metadata such as data set names, owners, business definitions, and access rules. Pair this with the business glossary to clarify terms and ensure everyone speaks the same language.
Many common platforms, such as Microsoft’s SharePoint, conform metadata according to some DCAT standards, such as author, date, and file type, but full compliance is not automatic. Luckily, most SMBs can create custom metadata columns, or, for more complicated systems, use managed metadata services to build taxonomies and term sets.
An MSP partner can help you sort through your options and create a data catalog system that’s appropriate to the size, scope, and budget needs of your business.
Step 4: Codify access and protection with Role Based Access Control (RBAC)
Now that you’ve identified your data by its sensitivity and usefulness, it’s time to classify it by who should have access to it. Define and document access controls using RBAC standards approved by the National Institute of science and technology. Most software systems are built for this kind of access control, so your MSP or internal IT department can help you set the parameters and permissions appropriately with the right tools and protocols. Set up for encryption for sensitive data, both at rest and in transit. Determine which data is automatically retained or archived, and which is automatically deleted after a defined period.
Step 5: If you’re using synthetic data, create a synthetic data policy with approved use cases, generation methods, validation checks, and labeling.
Does your organization need the information cloaking that synthetic data provides? If so, you’ll need to draft a synthetic data policy that specifically outlines how and when synthetic data can be used. For instance, is synthetic data used for masking health or purchase information? Or is it used in the training or testing phases only? The answer will determine how you craft policies and procedures around that synthetic data. Outline all the approved ways that this synthetic data can be generated, how it’s validated, and all its privacy and labeling requirements. Don’t forget to consider issues of bias, privacy, and compliance risks, referencing any data handling regulations your company is bound by.
Step 6: Pilot two quick win projects to test your data automation and synthetic datasets
Now that you have your rules in place, it’s time to execute. Choose two small scale projects to test and see if they run properly and demonstrate value quickly. You might try automating software tests with synthetic datasets or running a privacy-preserving analytics pilot. Document lessons learned and share results with stakeholders to build momentum. With results in hand, you can slowly roll out more staff training and new AI initiatives.
Step 7: Measure and iterate
The more data-driven projects you employ in your company, the more key performance indicators you’ll need. Established simple metrics to track progress, such as:
- Percentage of datasets cataloged
- Number of policy exceptions per month
- AI model defect rate (such as errors or bias incidents)
Hold regular data council meetings to review the results and iterate on policies and processes as needed.

Master data governance with effective management of your data, metadata, and synthetic data
Is mastering data governance a daunting process? Yes, very often. But here’s the good news: the time you spend implementing data governance will pay dividends for months or years to come. You’ll have accurate data, better results with AI, and an information foundation you can innovate upon.
If you need an MSP partner to help you mind the details of your data, Integris can help. We work with small and medium-size businesses across the United States with a full range of managed IT packages and IT consulting services. We’d love to help you get your systems ready for the AI era. Contact us today for a free consultation.





